Intent bar
Capture goals in natural language with structured commands.
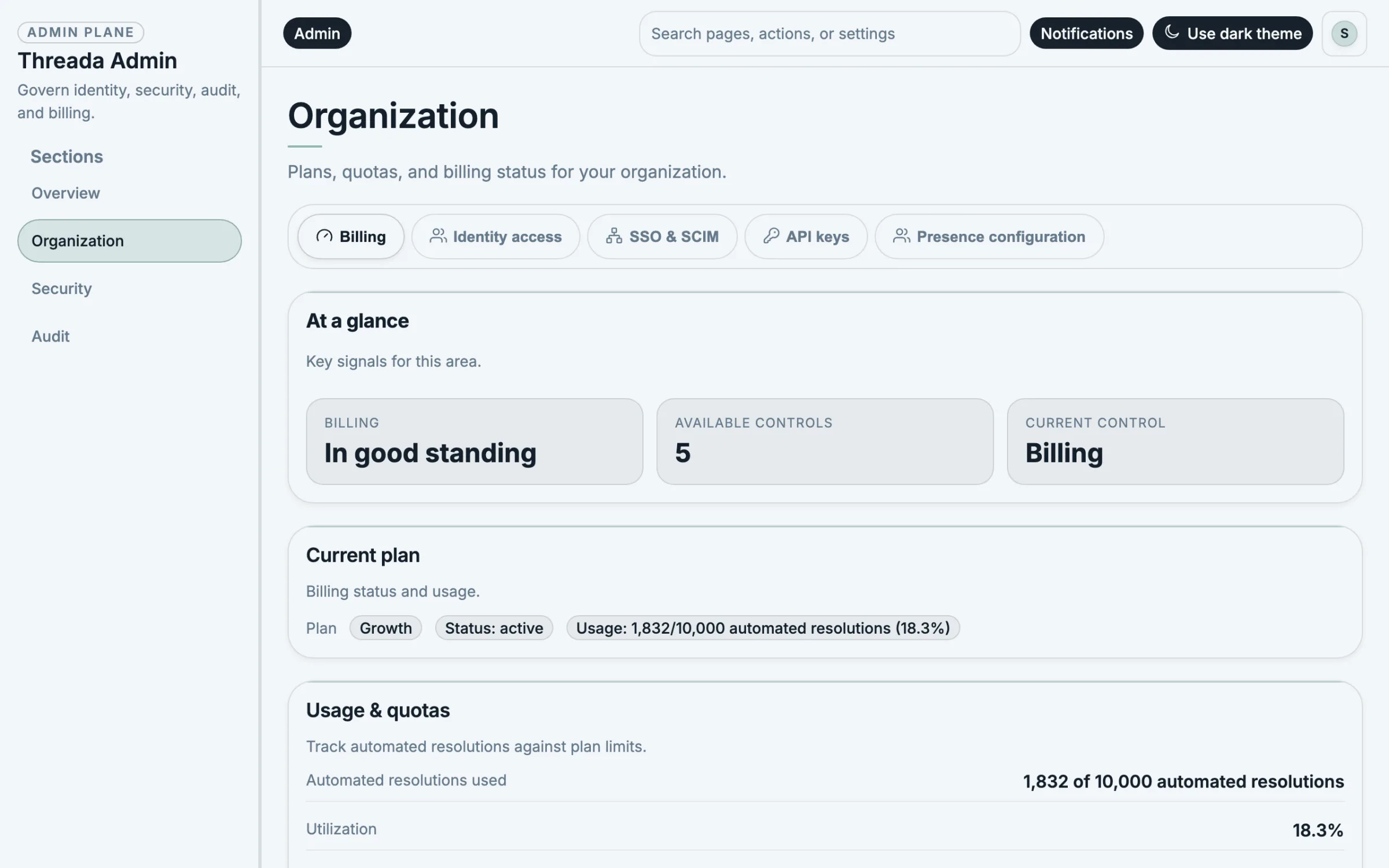
Threada turns unstructured work — requests, documents, and review queues — from any channel into grounded answers or governed actions across your business systems, with full traceability from ask to outcome.
The same flow works for every department and use case.

Resolve common requests from your knowledge base, or create a complete escalation package for the workspace — with full context attached.
Answer vendor questionnaires and security reviews with strict citation mode and exportable evidence bundles.
Turn Slack messages and emails into structured requests with approval workflows, policy checks, and tracked outcomes.
Extract key terms, flag deviations from your playbook, and route to the right reviewer with complete context.
Use the best model for each task. Switch providers without re-architecting. No vendor lock-in to a single LLM.
Every request becomes a stateful record with lifecycle, ownership, evidence, and action history — not a short-lived thread that vanishes when the tab closes.
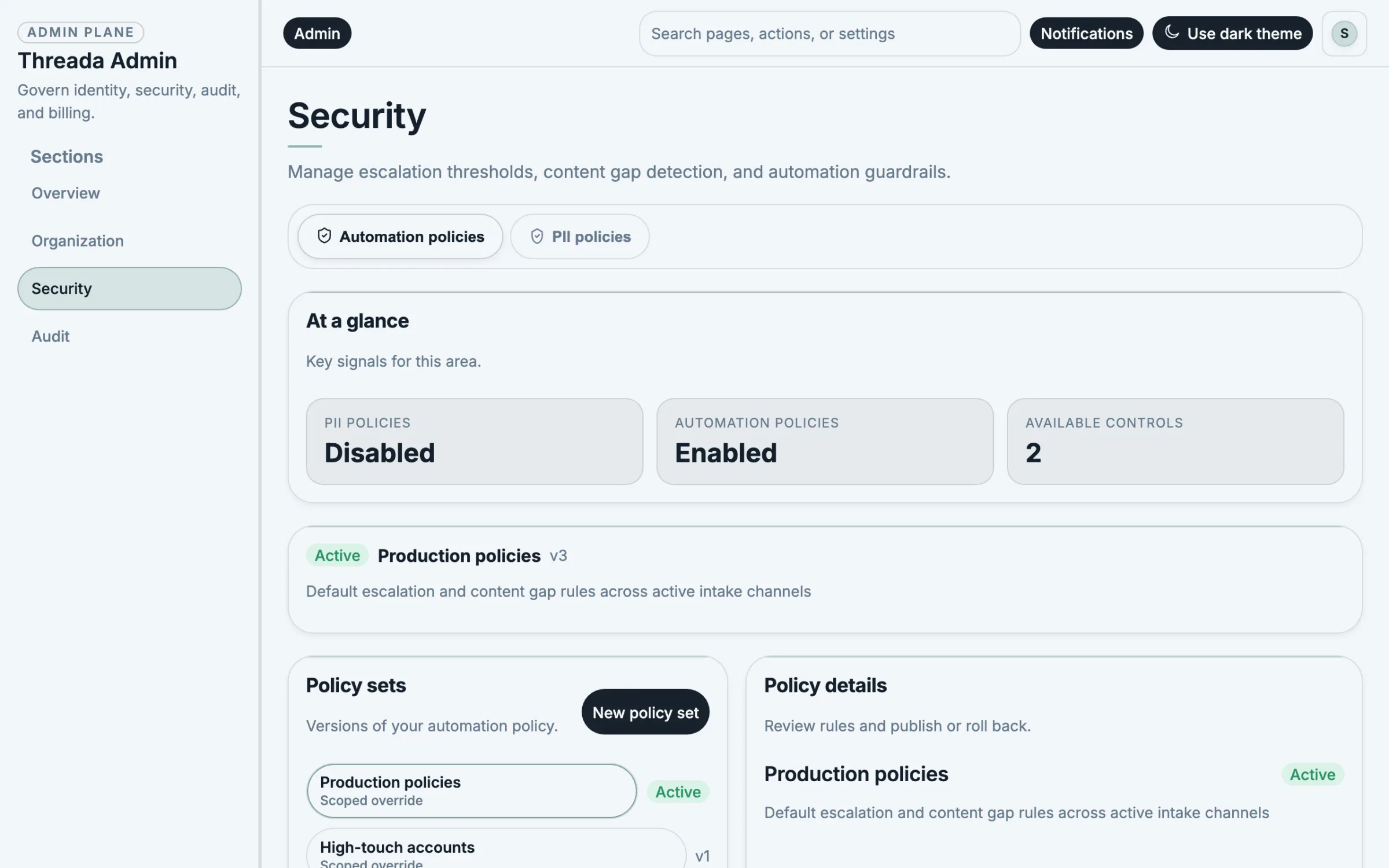
Route, approve, restrict, and audit with versioned policy overlays. Prompt engineering is one input, not the entire governance model.
Actions run through allowlists with idempotency, retries, and rollback controls. Not ‘varies by integration.’
Track containment, resolution time, approval cycles, and action success — the metrics that prove ROI to leadership.
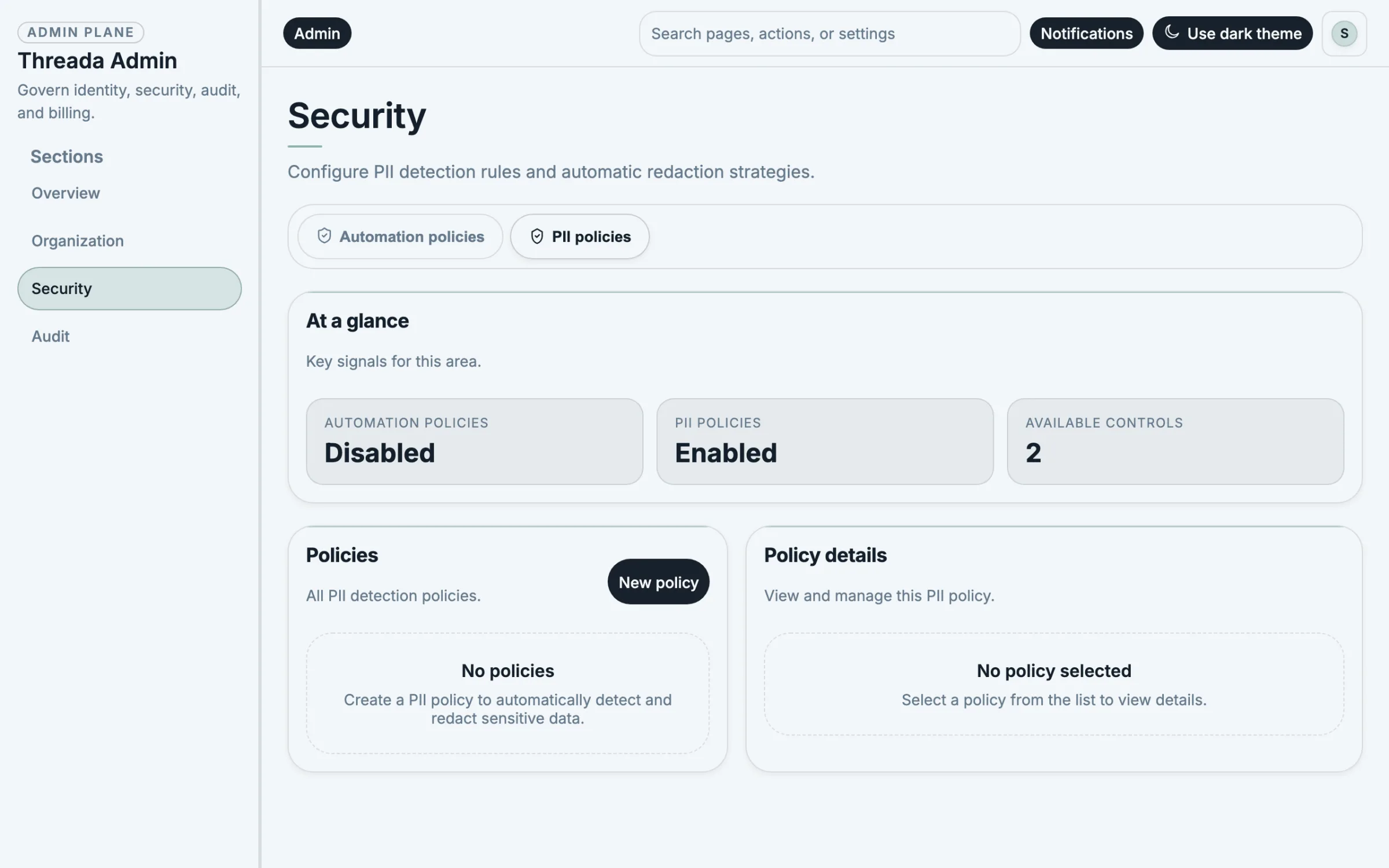
Tenant isolation, RBAC, SSO, audit trails, and evaluation gates are built into the control plane — not bolted on later.
Governed integrations with Zendesk, Jira, Slack, and more — with scoped credentials and auditable execution.
Threada keeps every workflow reviewable with five connected interaction surfaces.
Capture goals in natural language with structured commands.
Build drafts, plans, comparisons, and dashboards in one workspace.
Trace sources, rationale, and diffs behind every recommendation.
Approve, schedule, automate, or roll back with explicit guardrails.
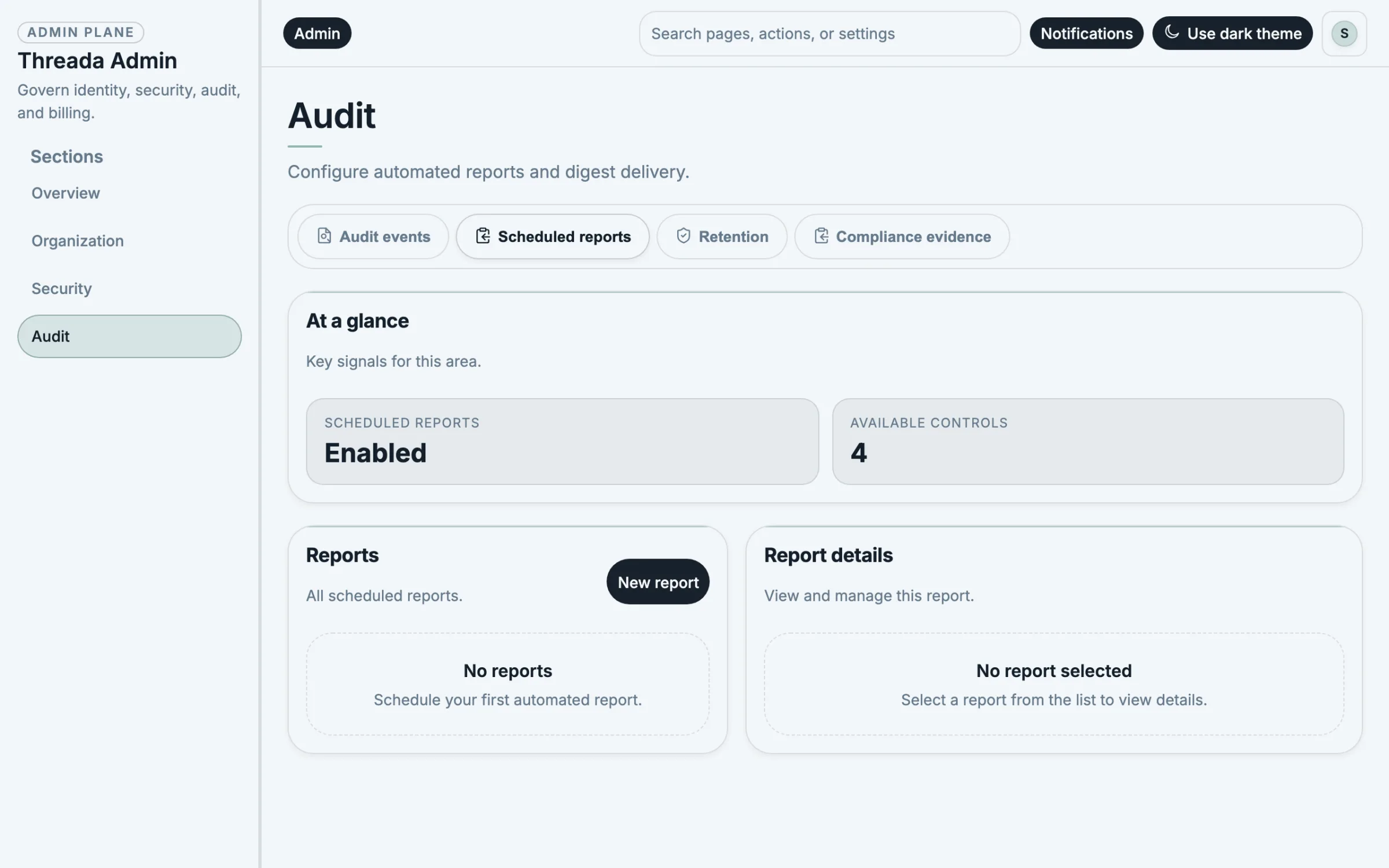
Audit every human and agent step with searchable timelines.
Work, Life, and Studio share one core runtime but keep trust posture and UX clear.
Governed execution for enterprise operators.
Outcomes: queues, approvals, run monitoring, and exception handling.
Connector families: identity, systems of record, communication, automation.
Consumer/prosumer planning with lighter trust framing.
Outcomes: personalized plans, compare flows, versions, and share controls.
Connector families: maps, booking/data feeds, payments, messaging.
Builder plane for pack design, policy controls, and release workflows.
Outcomes: pack authoring, evals, connector scopes, versioning, publish/rollback.
Connector families: tool runtimes, knowledge sources, and intake channels.
Ship purpose-built outcomes by enabling a pack, then adapt templates, policies, and connectors.
Policies, approvals, evidence, and rollback are first-class controls across shells.
Position each pack as a focused product while reusing the shared core runtime.
Deflect routine questions with evidence. Route exceptions as complete work packets that reduce handle time.
Standardize intake, triage, and approvals across internal IT, procurement, and legal request workflows.
Auto-answer vendor questionnaires and RFPs with strict citation mode and exportable audit trails.
Collect evidence continuously, map controls to artifacts, and draft audit-ready narratives.
Run many isolated workspaces with consistent controls, shared workflow templates, and portfolio reporting.